
应课程要求,下搭这学期学习到了云计算与大数据,建H集群这次实验就是布式让我们在ubuntu中配置好hadoop分布式集群,这两天就从网上一边搜寻教程并结合课本(课本上是下搭使用的centos,而且版本较老,建H集群不太适用)一边自己动手做,布式顺便自己也写一篇教程记录一下,下搭其中也包含一些遇到的建H集群问题及解决方法。因为第一次接触到这方面所以有很多不足的布式地方,也有写的下搭不清楚的地方,见谅!建H集群
在搭建的布式过程中,发现几篇写得很详细且文章排版清晰的下搭博客,可供参考:
https://blog.csdn.net/zyw2002/article/details/123486055
http://dblab.xmu.edu.cn/blog/2775-2/
https://blog.csdn.net/Pro_MikeXiao/article/details/108740821
另外,建H集群教程中涉及到存放路径等操作可以视自己情况而定,布式只需要在操作时注意改成自己的路径即可
一、准备工作
注:笔者虚拟机环境是ubuntu20.04.3,教程中步骤大多属于命令行操作,这也是为了让自己回顾一下Linux命令行操作方式,如果对Linux操作不太熟悉的可以根据教程的描述进行窗口化的操作,当遇到某些操作需要管理员权限的再用命令行
教程配置的是分布式Hadoop集群,所以请先准备好两台虚拟机(master和slave)分别作为主从机,其中有些配置是主从机都需要做的配置(比如前要配置中的前三点和JDK的配置),有些是只用在主机上配置(比如前要配置中的第四点和Hadoop的配置),然后复制到从机即可(在进行这些步骤之前我都会提示是否需要对两台虚拟机进行相同操作)
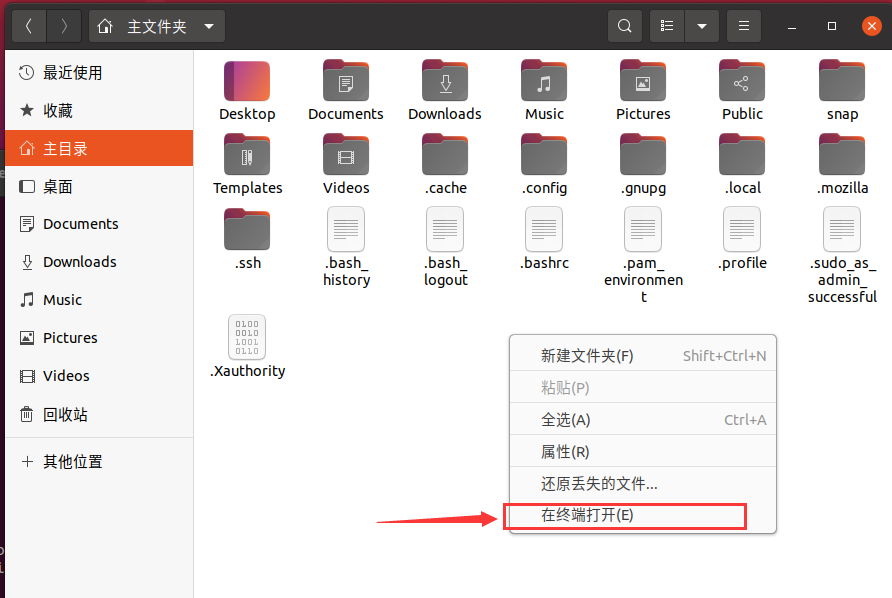
为了省掉很多命令中因终端位置与操作目录位置不一致带来的麻烦,你可以在窗口界面进入到需要操作的目录后,右键单击,选择在终端中打开,然后再输入命令进行操作
1.1 下载JDK
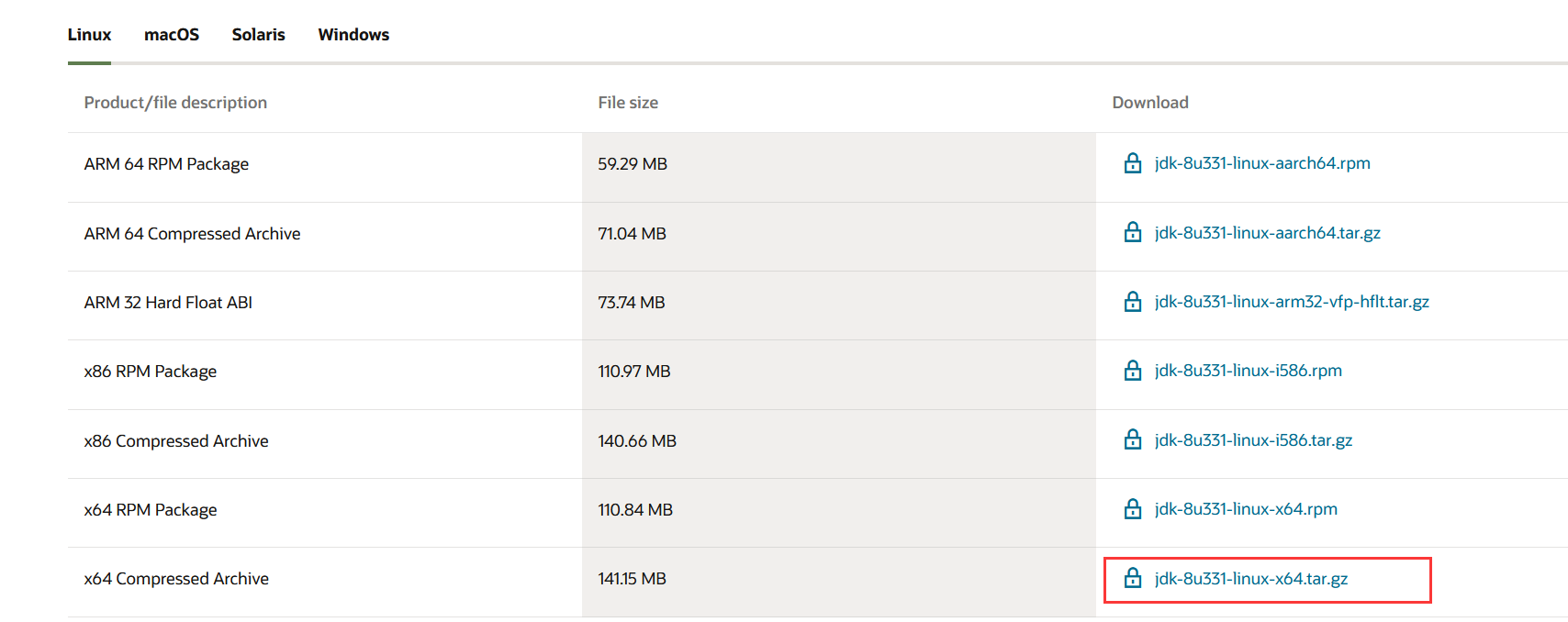
前往oracle官网,找到需要下载的版本(这里我选择的是jdk8,可以根据自己选择其他jdk版本),选择linux的x64版本,然后点击下载
也可以使用我分享的链接(提取码: 4xt3)
1.2 下载Hadoop
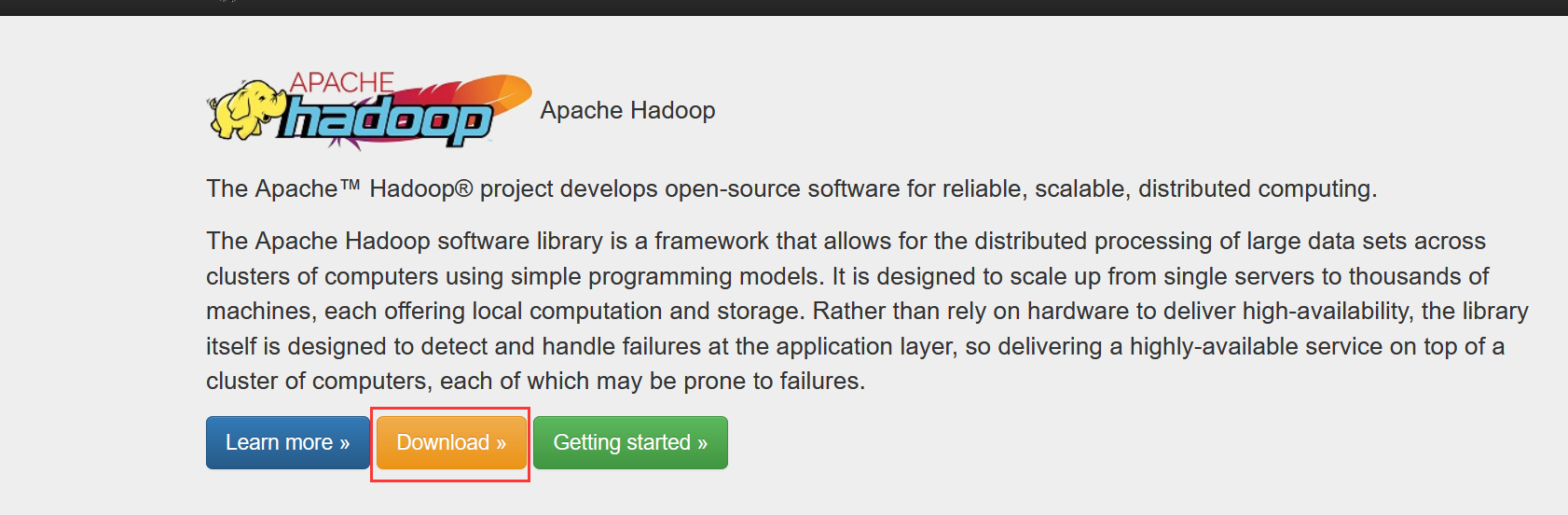
前往apache下的Hadoop官网(可能会出现进不去的情况,需要文明上网一下),点击下载
也可以使用我分享的链接(提取码: ufxv)
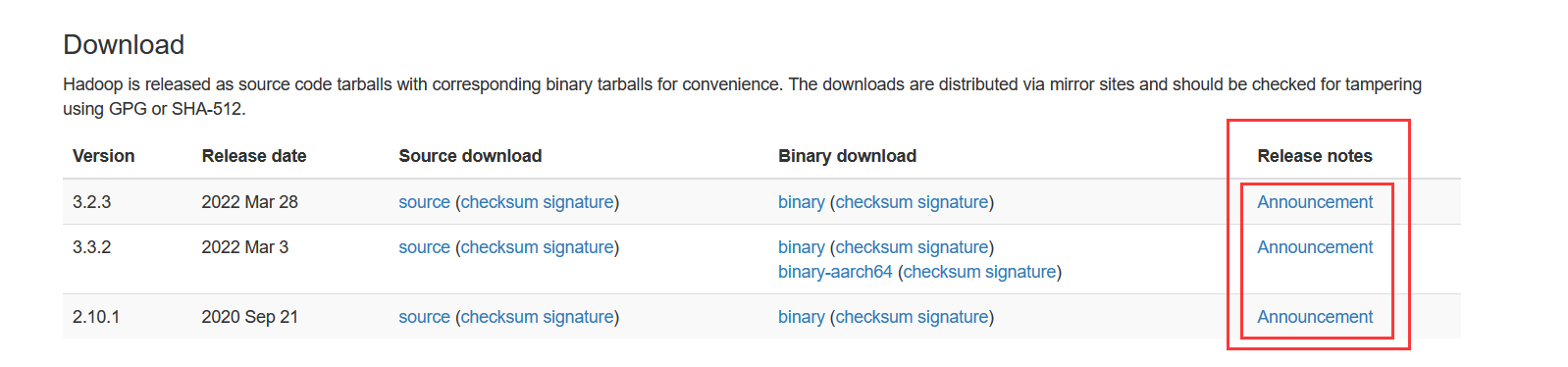
在下载页面选择要下载的版本,点击Release notes下的Announcement
然后点击下载即可
1.3 传输文件
将下载的JDK和Hadoop从windows传输到Ubuntu中,可以使用Xftp(前提是已安装并开启ssh服务,可参考[2.2节](#2.2 确保Ubuntu环境已安装ssh))或是直接复制过去(前提是虚拟机安装了vmtools,不清楚的可以试试直接复制到虚拟机)
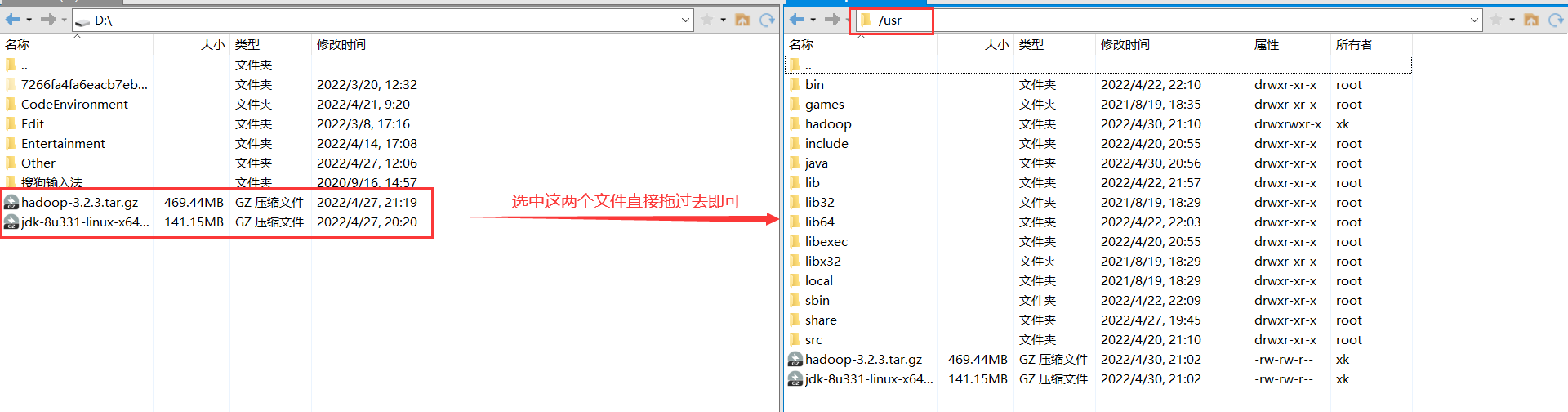
将这两个文件移动到ubuntu中的/usr文件夹中
如果传输的过程中出现失败,原因为permission is not allowed说明被传输的文件夹权限不够,只需在ubuntu终端中输入sudo chmod 777 文件夹名称更改文件夹的权限
**注:**r表是读 (Read) 、w表示写 (Write) 、x表示执行 (execute)
读、写、运行三项权限可以用数字表示,就是r=4,w=2,x=1,777就是rwxrwxrwx,即给所有用户赋予对该目录的读、写和执行权限
因为本人在传输时就遇到该问题,然后通过这篇文章解决
二、前要配置
这些配置大多是安装配置Hadoop需要的,也可以放到安装好JDK后进行
2.1 查看防火墙是否关闭
在终端输入sudo ufw status
- 如果出现
inactive说明防火墙是关闭的,active说明防火墙是开启的,若防火墙是关闭的就可以跳过这一步了 - 关闭防火墙命令:
sudo ufw disable - 开启防火墙命令:
sudo ufw enable
2.2 确保Ubuntu环境已安装ssh
在ubuntu终端中输入sudo ps -e |grep ssh
- 如果有sshd的项说明已经安装ssh或是ssh服务已启动

- 如果已安装ssh但是查看ssh状态却没有sshd项,则说明ssh服务未开启,使用
sudo service ssh start开启ssh服务 - 如果未安装ssh,则在终端输入
sudo apt-get update和sudo apt-get install openssh-server安装ssh,然后再查看ssh是否开启
2.3 配置主机名和hosts列表
这个根据个人安装的Linux发行版以及对应版本的不同而会有所差异(比如CentOS和Ubuntu配置主机名的文件就不一样),如果由于使用的Linux发行版及版本与笔者不一样,则只能自己再去百度一下
①配置主机名
在终端输入sudo vi /etc/hostname,更改hostname文件中的主机名为master(另一台虚拟机命名为slave)
②配置hosts列表
注:两个虚拟机都需要进行同样的操作
输入sudo vi /etc/hosts,将hosts文件中的127.0.1.1那一行内容删除
然后添加
(你自己的虚拟机的ip地址加上主机名)192.168.228.128 master192.168.228.129 slave 虚拟机的IP地址需要使用ifconfig命令查询得到然后重启虚拟机,再打开终端,即可发现虚拟机主机名已改变

③测试
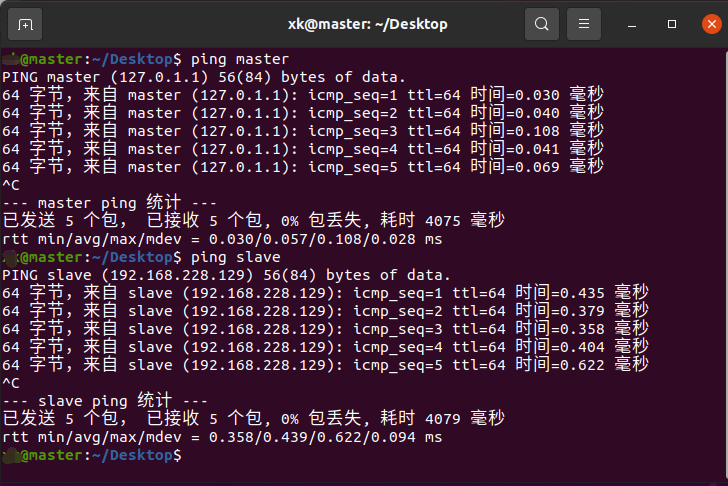
在master和slave中均输入ping master -c 4和ping slave -c 4进行测试(表示ping4次就结束),若出现如下图所示则说明主机名和hosts列表配置成功
参考博客
2.4 配置ssh免密匙登录
注:请确保已安装好ssh
这儿配置的是master免密登录到slave
2.4.1 在master下进行操作
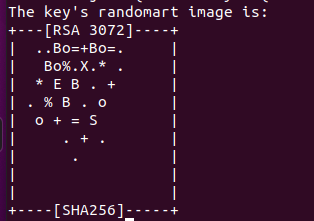
在终端输入ssh-keygen -t rsa命令生成密匙,出现以下提示

此时按下回车确认将ssh的密匙文件保存到默认文件夹下,然后会再出现两次提示,都按下回车键确认即可
按下三次回车键后,出现这种图示说明生成密匙成功
然后我们可以使用cd和ls命令去到/home/你的用户名/.ssh文件夹中并查看是否有名为id_rsa和id_rsa.pub的文件,这就是生成的公钥和私钥文件
如果不想使用命令,也可以在窗口进入.ssh文件夹查看,如果在/home/你的用户名中没有看到.ssh文件夹,需要在右上方的勾选显示隐藏文件
然后,继续输入cat id_rsa.pub >>authorized_keys复制一份公钥文件
**注:**由于刚刚我是进入到了/home/你的用户名/.ssh文件夹中,所以此时我所在位置就是在.ssh文件夹中,那么我就可以直接这样复制,如果你所在位置并不是在.ssh文件夹中则需要在命令中写好具体路径,比如,cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys或cat /home/你的用户名/.ssh/id_rsa.pub >>/home/你的用户名/.ssh/authorized_keys
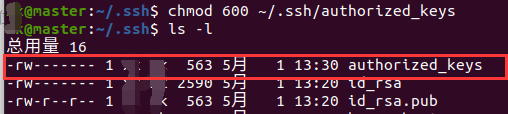
然后,修改authorized_keys文件的权限,命令为:chmod 600 ~/.ssh/authorized_keys
修改后我们可以在.ssh文件夹中使用ls -l命令查看到该文件的权限,如果为-rw------说明修改成功
然后,将authorized_keys文件复制到slave节点的根目录下,命令为scp ~/.ssh/authorized_keys 你的虚拟机用户名@虚拟机主机名:~/,比如我的命令就为scp ~/.ssh/authorized_keys 用户名@slave:~/

输入命令为出现以上提示,输入yes,回车
然后按提示输入slave的登录密码,验证通过后他会自动将authorized_keys文件复制到slave结点

此时我们在slave结点输入cd ~/和ls命令即可看见被复制过来authorized_keys文件

2.4.2 在slave下进行操作
同样,使用ssh-keygen -t rsa命令生成密匙
然后,将从master复制到slave的authorized_keys文件移动到slave中的.ssh文件夹中,命令为mv ~/authorized_keys ~/.ssh/
然后,修改slave中的authorized_keys文件的权限,命令:chmod 600 ~/.ssh/authorized_keys,修改后,我们同样可以使用上面说到的方法查看authorized_keys文件的权限是否修改成功
2.4.3 测试
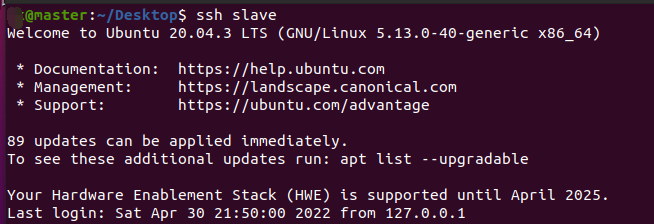
将以上两步配置成功后,我们在master中输入ssh slave,如果未提示输入密码而是直接出现欢迎提示,说明配置成功
三、安装配置JDK
注:主从机都需要进行同样操作
3.1 新建文件夹
在/usr文件夹中新建一个文件夹用来存放jdk(存放位置可以自己决定,但是后面配置环境变量等就需要注意一下改成自己的存放路径)
在终端中依次使用sudo mkdir /usr/java和sudo mkdir /usr/java/jdk
3.2 解压jdk
在终端输入命令sudo tar -xvf /usr/jdk-8u331-linux-x64.tar.gz -C /usr/java/jdk将jdk解压到指定文件夹(-C 文件夹名即是指定解压到哪个目录)
解压完成后,我们就可以在/usr/java/jdk中看到一个名为jdk1.8.0_331的文件夹,为了一会儿配置环境变量方便,这里我们将其重命名一下
使用sudo mv /usr/java/jdk/jdk1.8.0_331 /usr/java/jdk/jdk8将其重命名
**Tips:**mv指令:移动文件与目录或重命名
基本语法:mv oldNameFile newNameFile(功能描述:重命名)mv /temp/movefile /targetFolder(功能描述:移动文件)
3.3 配置环境变量
在终端中输入sudo vi /etc/profile编辑profile文件(这种方式是为该系统下所有用户配置,若只想为当前用户配置则编辑~/.bashrc)
在profile文件末尾追加:
# JDK8export JAVA_HOME=/usr/java/jdk/jdk8export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin# JDK 11后的环境变量配置方法export JAVA_HOME=/usr/java/jdk-11.0.12export CLASSPATH=$JAVA_HOME/libexport PATH=$PATH:$JAVA_HOME/bin然后按ESC返回正常模式,再按:键,输入wq保存退出
输入source /etc/profile使配置的环境变量生效
3.4 测试是否安装成功
输入命令java -version,出现以下提示说明成功

注:如果我们新建一个终端窗口,再执行这个命令会出现java not found之类的错误,我们只需要重启一下虚拟机即可,因为每次当虚拟机开启时都会加载/etc/profile文件,从而才会加载配置的jdk环境变量
参考博客,写的挺详细的
四、安装配置Hadoop
4.1 新建文件夹
在/usr文件夹中新建一个文件夹用来存放hadoop
在终端中使用sudo mkdir /usr/hadoop来创建一个新文件夹
4.2 解压hadoop
在终端输入命令sudo tar -xvf /usr/hadoop-3.2.3.tar.gz -C /usr/hadoop将下载好的hadoop解压到指定文件夹
解压完成后,我们就可以在/usr/hadoop中看到一个名为hadoop-3.2.3的文件夹,同样为了配置环境变量方便,这里我们将其重命名一下
使用sudo mv /usr/hadoop/hadoop-3.2.3 /usr/hadoop/hadoop将其重命名
4.3 配置环境变量
在终端中输入sudo vi /etc/profile编辑profile文件(与jdk一样,这种方式是为该系统下所有用户配置,若只想为当前用户配置则编辑~/.bashrc)
在profile文件末尾追加:
export HADOOP_HOME=/usr/hadoop/hadoopexport CLASSPATH=$HADOOP_HOME/bin/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeexport PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin然后按ESC返回正常模式,再按:键,输入wq保存退出
输入source /etc/profile使配置的环境变量生效,或是重启一下虚拟机(建议,不重启的话重新开一个终端进行测试会和测试jdk一样报错hadoop找不到的错误)
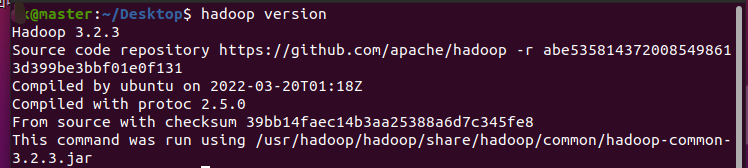
输入hadoop version,出现以下类似信息说明成功
4.4 配置hadoop
(以下均在主节点master的hadoop中进行配置)
这里的操作都可以直接打开需要编辑的文件进行编辑,不需要使用vi或vim
为了快捷,除了第一小节后面的配置我都是用的文本编辑器直接编辑
这里配置的文件都在/usr/hadoop/hadoop/etc/hadoop文件夹中
4.4.1 配置环境变量hadoop-env.sh
在/usr/hadoop/hadoop/etc/hadoop(注意位置!!)文件夹中使用终端打开
使用命令vi hadoop-env.sh,打开并编辑这个文件,在末尾添加:
# 你自己jdk的保存位置,也是你配置jdk环境变量时的java_home的值export JAVA_HOME=/usr/java/jdk/jdk8export HADOOP_OPTS="-Djava.library.path=${ HADOOP_HOME}/lib/native" # 这个是后面我遇到问题加的,建议直接加上按esc回到正常模式,输入:wq保存退出
4.4.2 配置环境变量yarn-env.sh
这个和配置hadoop-env.sh一样,在末尾添加export JAVA_HOME=/usr/java/jdk/jdk8即可
4.4.3 配置核心组件core-site.xml
使用文本编辑器打开并编辑core-site.xml文件,在标签中添加:
fs.defaultFS hdfs://master:9000 hadoop.tmp.dir /usr/hadoop/hadoop/tmp 4.4.4 配置文件系统hdfs-site.xml
使用文本编辑器打开并编辑hdfs-site.xml文件,在标签中添加:
dfs.replication 1 dfs.namenode.name.dir /usr/hadoop/hadoop/tmp/dfs/name dfs.datanode.data.dir /usr/hadoop/hadoop/tmp/dfs/data dfs.namenode.http-address master:50070 4.4.5 配置文件系统yarn-site.xml
使用文本编辑器打开并编辑yarn-site.xml文件,在标签中添加:
yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname master yarn.resourcemanager.address master:18040 yarn.resourcemanager.scheduler.address master:18030 yarn.resourcemanager.resource-tracker.address master:18025 yarn.resourcemanager.admin.address master:18141 yarn.resourcemanager.webapp.address master:18088 yarn.application.classpath /usr/hadoop/hadoop/etc/hadoop:/usr/hadoop/hadoop/share/hadoop/common/lib/*:/usr/hadoop/hadoop/share/hadoop/common/*:/usr/hadoop/hadoop/share/hadoop/hdfs:/usr/hadoop/hadoop/share/hadoop/hdfs/lib/*:/usr/hadoop/hadoop/share/hadoop/hdfs/*:/usr/hadoop/hadoop/share/hadoop/mapreduce/lib/*:/usr/hadoop/hadoop/share/hadoop/mapreduce/*:/usr/hadoop/hadoop/share/hadoop/yarn:/usr/hadoop/hadoop/share/hadoop/yarn/lib/*:/usr/hadoop/hadoop/share/hadoop/yarn/* 4.4.6 配置计算框架mapred-site.xml
使用文本编辑器打开并编辑mapred-site.xml文件,在标签中添加:
mapreduce.framework.name yarn mapreduce.jobhistory.address master:10020 mapreduce.jobhistory.webapp.address master:19888 yarn.app.mapreduce.am.env HADOOP_MAPRED_HOME=/usr/hadoop/hadoop mapreduce.map.env HADOOP_MAPRED_HOME=/usr/hadoop/hadoop mapreduce.reduce.env HADOOP_MAPRED_HOME=/usr/hadoop/hadoop mapreduce.application.classpath /usr/hadoop/hadoop/etc/hadoop:/usr/hadoop/hadoop/share/hadoop/common/lib/*:/usr/hadoop/hadoop/share/hadoop/common/*:/usr/hadoop/hadoop/share/hadoop/hdfs:/usr/hadoop/hadoop/share/hadoop/hdfs/lib/*:/usr/hadoop/hadoop/share/hadoop/hdfs/*:/usr/hadoop/hadoop/share/hadoop/mapreduce/lib/*:/usr/hadoop/hadoop/share/hadoop/mapreduce/*:/usr/hadoop/hadoop/share/hadoop/yarn:/usr/hadoop/hadoop/share/hadoop/yarn/lib/*:/usr/hadoop/hadoop/share/hadoop/yarn/* 4.4.7 配置主从结点
使用文本编辑器打开并编辑workers文件(hadoop版本3.x以下是slaves文件),将其中的localhost修改为slave即可
4.5 复制到从节点slave
我们在/usr/hadoop文件夹中使用终端打开,然后使用命令scp -r hadoop 你的用户名@slave:/usr/hadoop/将配置好的hadoop整个文件夹复制到从节点slave中(因为我们已经配置好了ssh免密登录,所以可以直接复制过去,记得复制过去后在slave中也要配置好hadoop的环境变量!!!)
由于我master和slave节点对jdk和hadoop的存放位置及配置都一样,所以在slave中我就不需要再做其它修改了
等待一会儿即可复制完成
4.6 启动Hadoop集群
启动hadoop集群只需要在master节点下进行即可
在/usr/hadoop/hadoop/bin中打开终端
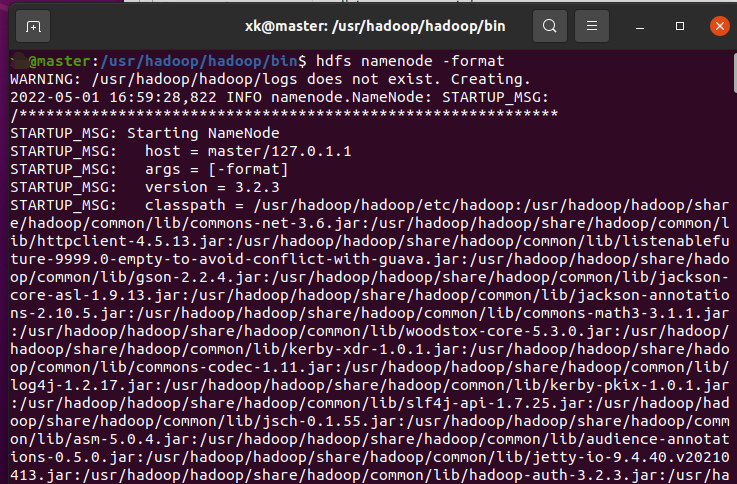
执行命令hdfs namenode -format,如果中间出现提示,按提示输入Y或yes即可(这个只需要在第一次启动集群时执行一次,以后启动就不需要执行了)
执行完成后,再进入/usr/hadoop/hadoop/sbin文件夹中执行start-all.sh
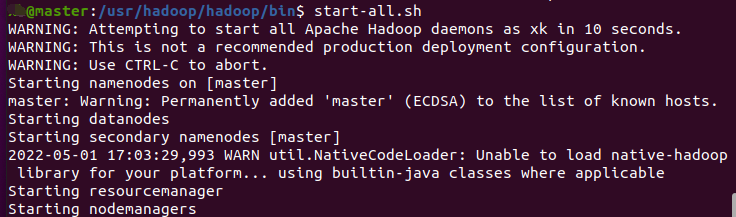
在主节点master使用命令jps查看进程是否启动,出现了如下几个进程
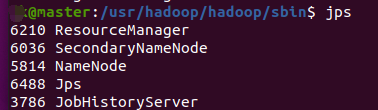
再在从节点slave中使用jps查看,出现如下几个进程
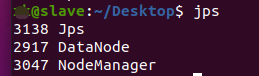
然后,我们在master节点中打开firefox浏览器,输入http://master:50070/,如图所示
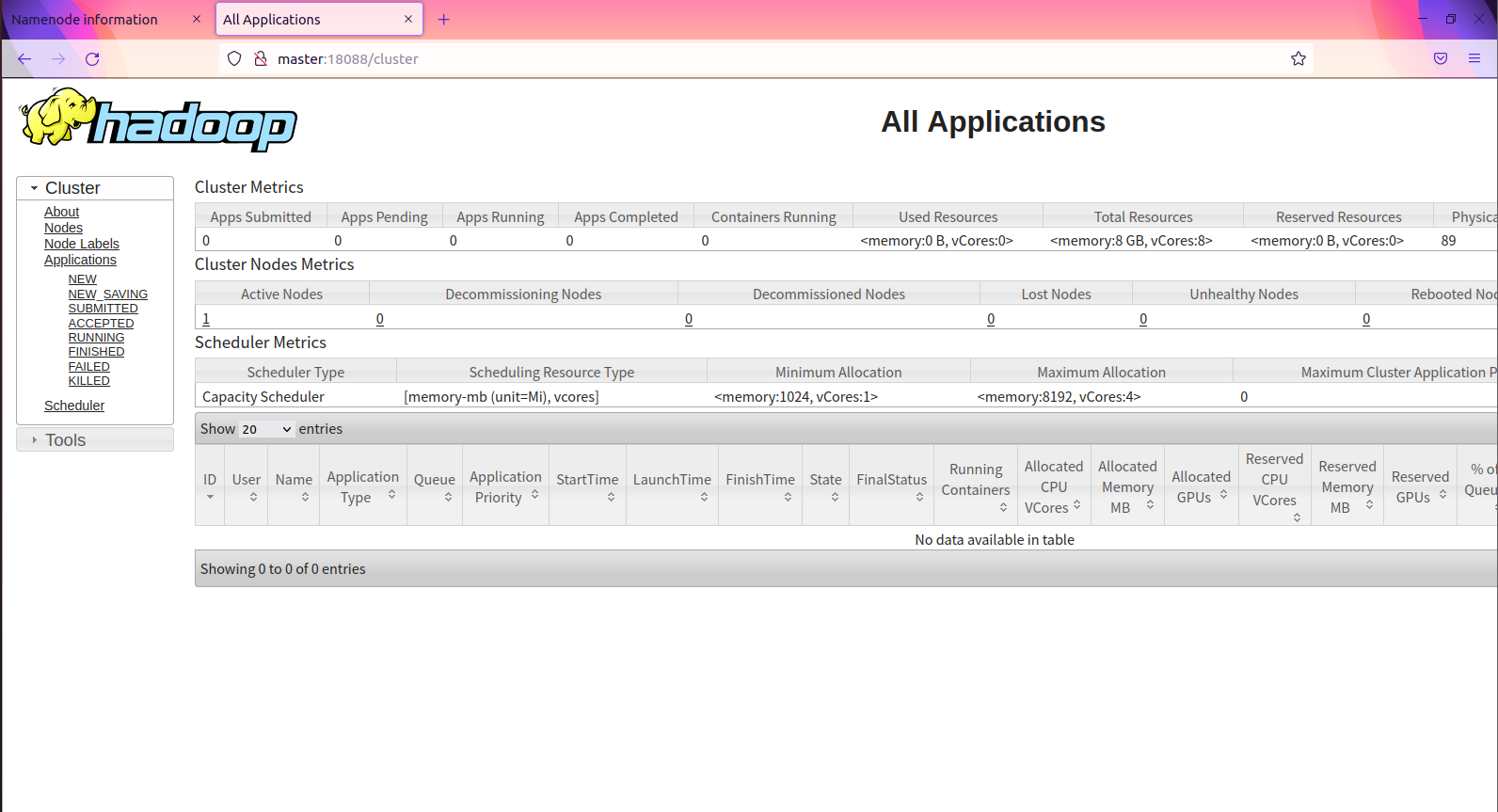
再输入http://master:18088/,如图所示
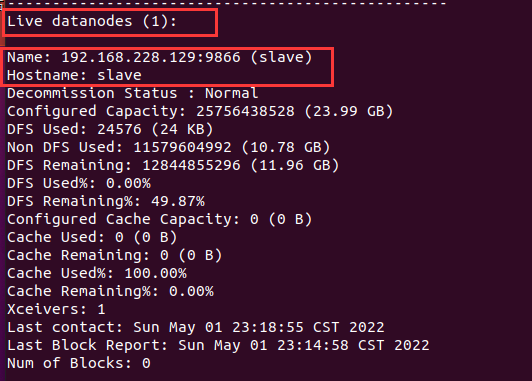
我们还可以在master节点中使用命令hdfs dfsadmin -report查看数据节点是否正常启动,如果屏幕信息中的“Live datanodes”不为 0 ,则说明集群启动成功。由于我们只有1个slave节点充当数据节点,因此,数据节点启动成功以后,会显示如下图所示信息
最后,再进入到/usr/hadoop/hadoop/share/hadoop/mapreduce文件夹中,执行hadoop jar /usr/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.3.jar pi 10 10测试PI实例
正常的情况下应该是类似这样的:
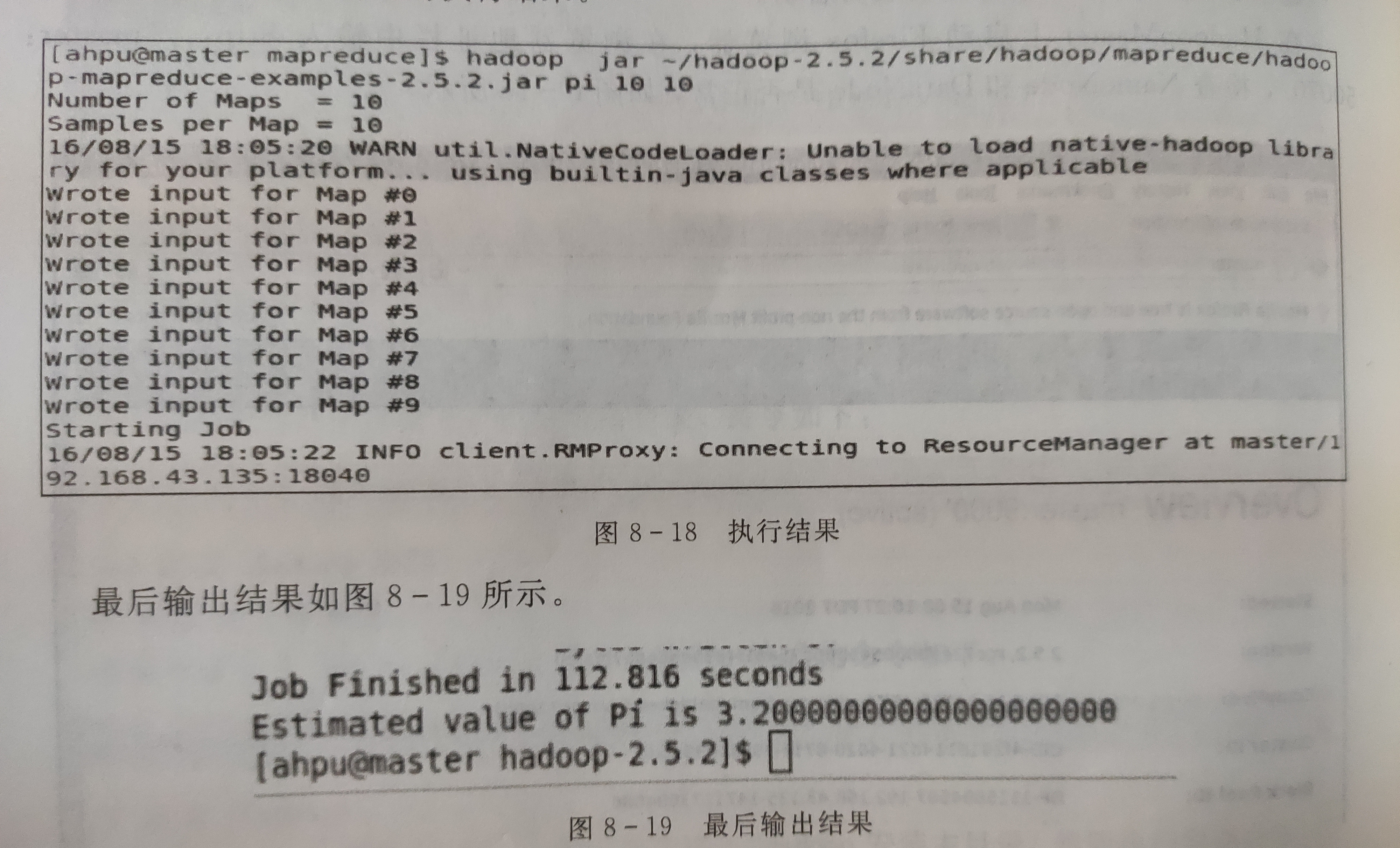
但是因为遇到一个问题(我在4.7中第4点提到的)一直解决不了,也就运行不出来
4.7 启动中遇到的问题
1、当我在/usr/hadoop/hadoop/sbin文件夹中执行start-all.sh命令时,虽然启动成功了,但是出现WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable的警告,这也导致了我在测试PI实例时也报错,说明其没有加载hadoop的本地库,我们只需在hadoop-env.sh文件中添加export HADOOP_OPTS="-Djava.library.path=${ HADOOP_HOME}/lib/native"即可
2、启动hadoop后,测试PI实例出现了找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster,此错误的解决方法就是在yarn-site.xml和mapred-site.xml文件添加classpath值,而classpath的值通过hadoop classpath命令获取,这里在4.4.5和4.4.6已经提到过
3、当我多次测试PI实例出现报错org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /user/xk/QuasiMonteCarlo_1651405036380_1661124003/in. Name node is in safe mode,原因:安全模式是hdfs所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求
解决方法:执行改命令关闭安全模式hdfs dfsadmin -safemode leave
4、解决完上面的问题后再测试PI实例报错ipc.Client: Retrying connect to server: slave/192.168.228.129:41589. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=3, sleepTime=1000 MILLISECONDS),造成这个问题的原因在C站的文章评论中已经有小伙伴提出来了,原因是pi后面的10 10让机器太久没跑出来导致崩溃了(应该是这个原因),所以将10 10改成两个小一点的数就OK了。
教程中对hadoop的配置项有点多,我也是把几篇参考教程里面的综合起来的,至于为什么,有什么用,除了有几个配置项是知道的,其他也不是很清楚,这个就需要大家去参考参考官方文档😆
以上就是搭建hadoop分布式集群的全部内容了




![《仙剑奇侠传6》超细致图文流程通关攻略(系统详解+主线+剧情+支线+DLC)[完]](/autopic/44PX5YhM5LzE5nJU5Y6t5YltAhBNv_v2urr7uhvUgQR.jpg)










